
A few years back, I went to visit a company that had managed to achieve a high level of agility without high levels of coaching or training, shipping several times a day. I was curious as to how they had done it. It turned out to be a product of a highly experimental culture, and we spent a whole day swapping my BDD knowledge for their stories of how they managed to reach the place they were in.
While I was there, I saw a very interesting graph that looked a bit like this:
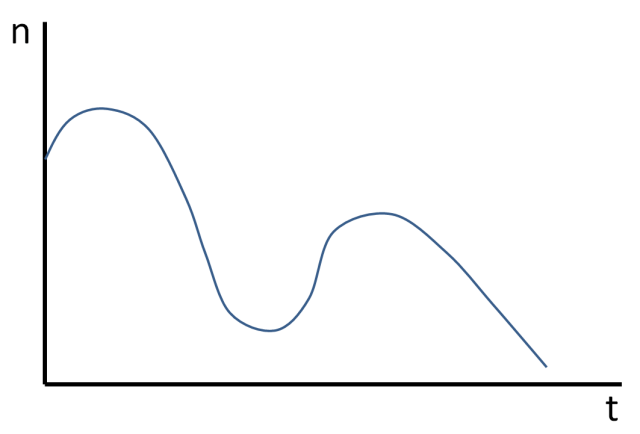
“That’s interesting,” I said. “Is that your bug count over time? What happened?”
“Well,” one of them said, “we realised our bug count was growing, so we hired a new developer. We thought we’d rotate our existing team through a bug-fixing role, and we hypothesized that it would bring the bug count down. And it worked, for a while – that’s the first dip. It worked so well, we thought we’d hire another developer, so that we could rotate another team member, and we thought that would get rid of the bugs… but they started going up again.”
“Ah,” I said wisely. “The developer was no good?” (Human beings like to spot patterns and think they understand root causes – and I’m human too.)
“Nope.” They were all smiling, waiting for me to guess.
“Two new people was just too many? They got complacent because someone was fixing the bugs? The existing team was fed up of the bug-fixing role?” I ran through all the causes I could think of.
“Nope.”
“All right. Who was writing the bugs?” I asked.
“Nobody.”
I was confused.
“The bugs were already there,” one of them explained. “The users had spotted that we were fixing them, and started reporting them. The bug count going up… that was a good thing.”
And I looked at the graph, and suddenly understood. I didn’t know Cynefin back then, and I didn’t understand complexity, but I did understand perverse incentives, and here was a positive version. In retrospect, the cause was obvious. It’s the same reason why crime goes up when policemen patrol the streets; because it’s easier to report it.
Conversely, a good way to have a low bug count is to make it hard to report. I spent a good few years working in Waterfall environments, and I can remember the arguments I had about whether something in my work was genuinely a bug or not… making it much harder for anyone testing my code, which meant I looked like a good developer (I really wasn’t).
Whenever we do anything in a complex system, we get unexpected side-effects. Another example of this is the Hawthorne effect, which goes something like this:
“Do you work better in this factory if we turn the lights up?”
“Yes.”
“Do you work better if we turn the lights down?” (Just checking our null hypothesis…)
“Yes.”
“What? Um, that’s confusing… do you work better with the lights up, or down?”
“We don’t care; just stop watching us.”
We’ve all come across examples of perverse incentives, which are another kind of unintended consequence. This is what happens when you turn measurements into targets.
When you’re creating a probe, it’s important to have a way of knowing it’s succeeding or failing, it’s true… but the signs of success or failure may only be clear in retrospect. A lot of people who create experiments to try get hung up on one hypothesis, and as a result they obsess over one perceived cause, or one measurement. In the process they might miss signs that the experiment is succeeding or failing, or even misinterpret one as the other.
Rather than having a hypothesis, in complexity, we want coherence – a realistic reason for thinking that the probe might have a good impact, with the understanding that we might not necessarily get the particular outcome we’re thinking of. This is why I get people creating probes to run through multiple scenarios of success or failure, so they think about what things they might want to be watching, or how they can put appropriate signals in place, to which they can apply some common sense in retrospect.
As we’ve seen, watching is itself an intervention… so you probably want to make sure it’s safe-to-fail.

So, are you saying that we aim to improve the wholeness of a system, by doing experiments based on hypothesis. That is, the hypothesis should express an expected improvement on wholeness or health (and thus express a means to guage that objectively)?
Martien, for some reason I missed this; apologies for taking a year to reply!
In complexity, a hypothesis is just an example of what you might see. It’s a possible way in which things might improve, for whatever you define as “improvement”.
You might also see the complete opposite, and that might still be representative of a good impact! So treat your hypotheses with curiosity, and don’t make them into targets.
Coherence is one of the trickier concepts in Cynefin; it’s worth reading through Dave Snowden’s writings on the subject http://cognitive-edge.com/blog/thinking-about-coherence/
Pingback: Java Web Weekly, Issue 124 | Baeldung